I spent three hours last week watching my API costs balloon because of one document.
Not a video. Not a massive dataset. Just a 10-page PDF that needed OCR processing. The problem? Traditional OCR pipelines were spitting out thousands of tokens that my LLM had to chew through. Every. Single. Page.
That's when I stumbled upon DeepSeek-OCR, and honestly, the numbers looked too good to be true.
The Token Problem Nobody Talks About
Here's the thing about modern LLMs: they're expensive. Not because the models are bad, but because context windows eat tokens like candy.
Let's say you're building a document processing pipeline. You scan an invoice, extract text with OCR, then feed it to GPT-4 for analysis. Simple, right? But that 1000-word document becomes 1000+ tokens. Multiply that by hundreds of documents daily, and suddenly you're bleeding money.
Traditional OCR treats text as... well, text. One character, one token. Makes sense, until you realize there might be a smarter way.
What if Text Could Be Compressed Visually?
DeepSeek-OCR flips the script completely. Instead of converting images to text tokens, it keeps them as vision tokens - compressed visual representations that carry the same information but use way fewer tokens.
Think of it like this: you could describe a stop sign with 50 words, or you could just show someone the octagon shape and red color. Same information, drastically different bandwidth.
The team at DeepSeek asked a fascinating question: "For a document with 1000 words, how many vision tokens do we actually need to decode it accurately?"
The answer shocked me: around 100 tokens. That's a 10× compression.
The Architecture: Two Parts, One Goal
DeepSeek-OCR uses a two-stage pipeline that's surprisingly elegant.
Stage 1: DeepEncoder (~380M parameters)
This is the compression engine. It takes high-resolution document images and squeezes them into a minimal set of vision tokens while keeping activations low. The secret sauce? It combines SAM-base (80M) and CLIP-large (300M) in series with a 16× convolutional compressor.
What I love about this design: it doesn't just blindly reduce tokens. It maintains low activation memory even with massive images, which means you won't run into GPU memory issues with large documents.
Stage 2: MoE Decoder (~3B parameters)
The decoder (DeepSeek3B-MoE-A570M) takes those compressed vision tokens and reconstructs the text. It uses a Mixture-of-Experts architecture, which basically means different "expert" networks handle different parts of the task in parallel.
Here's where it gets interesting: the decoder doesn't just do OCR. It understands layout, preserves formatting, and can output structured Markdown. It's not reading text-it's understanding documents.
Show Me the Numbers
I'm a skeptic by nature, so I needed concrete data. Here's what the benchmarks show:
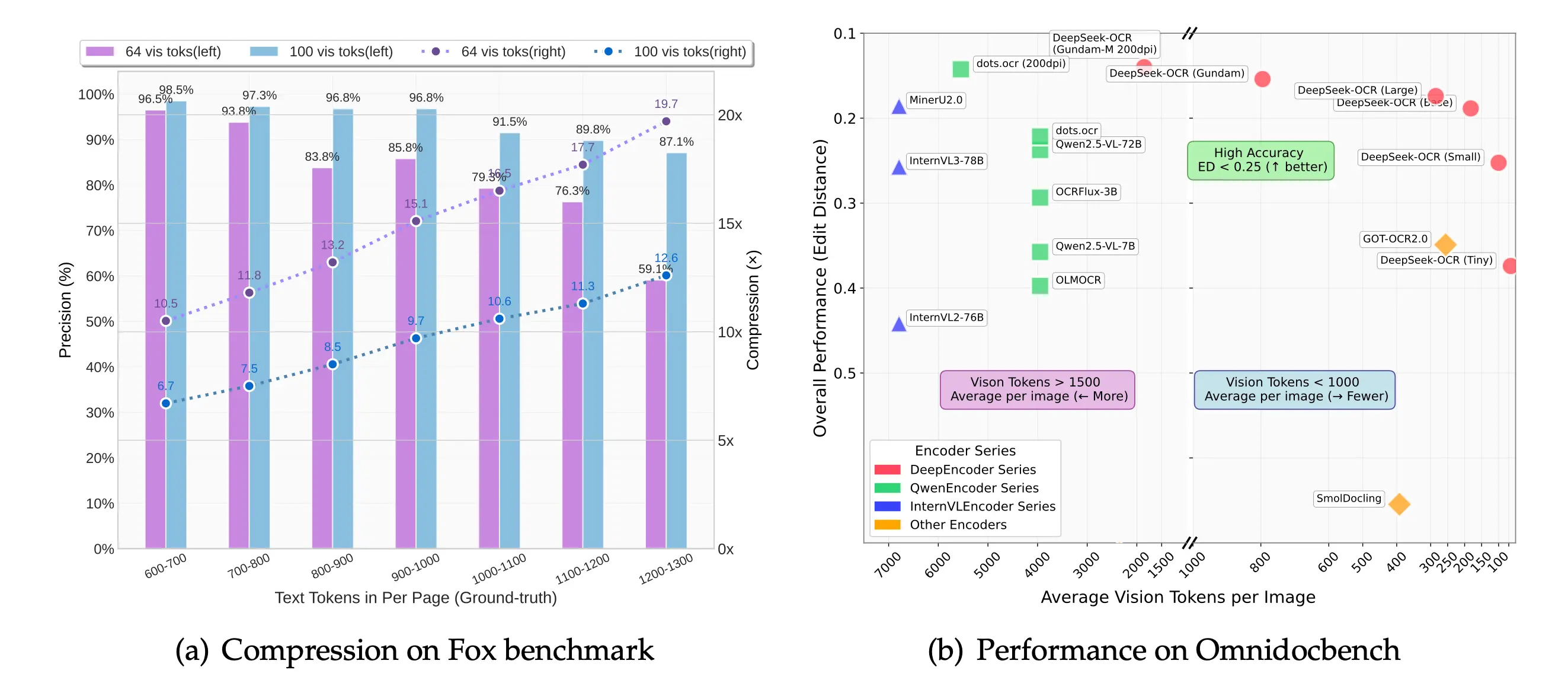
Compression vs. Accuracy Trade-off
According to the arXiv paper (v1):
"When the number of text tokens is within 10 times that of vision tokens (i.e., a compression ratio < 10), the model can achieve decoding (OCR) precision of 97%. Even at a compression ratio of 20, the OCR accuracy still remains at about 60%."
Let me break this down:
- 10× compression: ~97% precision (nearly lossless)
- 20× compression: ~60% accuracy (acceptable for certain use cases)
The sweet spot is clearly around 10×, where you get massive token savings without sacrificing quality.
OmniDocBench: The Real Performance Test
The team tested DeepSeek-OCR against two popular alternatives on OmniDocBench. The results are pretty stark:
| Model | Tokens per Page | Performance |
|---|---|---|
| GOT-OCR 2.0 | 256 | Baseline |
| DeepSeek-OCR | ~100 | Better |
| MinerU 2.0 | 6000+ | Worse |
DeepSeek-OCR beats GOT-OCR 2.0 while using 60% fewer tokens. And compared to MinerU 2.0? It's not even close-under 800 tokens vs 6000+.
Production Throughput
If you're wondering about real-world performance, the numbers from their official blog are wild:
- Single A100-40G: 200,000+ pages per day
- 20-node cluster (160× A100): 33 million pages per day
With vLLM, they're seeing ~2,500 tokens/s for PDF processing on an A100-40G.
Getting Your Hands Dirty: Setup
I tried this on my local setup. Here's what you need:
Environment Setup
# Create fresh conda environment
conda create -n deepseek-ocr python=3.12.9 -y
conda activate deepseek-ocr
# Install PyTorch (CUDA 11.8)
pip install torch==2.6.0 torchvision==0.21.0 torchaudio==2.6.0 \
--index-url https://download.pytorch.org/whl/cu118
# Clone the repo
git clone https://github.com/deepseek-ai/DeepSeek-OCR.git
cd DeepSeek-OCR
# Install dependencies
pip install -r requirements.txt
# Optional but recommended: FlashAttention
pip install flash-attn==2.7.3 --no-build-isolation
One gotcha: if you're using vLLM, you'll need the 0.8.5 wheel for CUDA 11.8. Download it from vLLM releases before installing.
Quick Start with Transformers
The simplest way to test it:
from transformers import AutoModel, AutoTokenizer
import torch
model_name = 'deepseek-ai/DeepSeek-OCR'
# Load model with FlashAttention (faster)
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
model = AutoModel.from_pretrained(
model_name,
_attn_implementation='flash_attention_2',
trust_remote_code=True,
use_safetensors=True,
)
model = model.eval().cuda().to(torch.bfloat16)
# Run OCR on a document image
prompt = "<image>\n<|grounding|>Convert the document to markdown."
image_file = 'invoice.jpg'
result = model.infer(
tokenizer,
prompt=prompt,
image_file=image_file,
base_size=1024,
image_size=640,
crop_mode=True,
save_results=True,
)
Resolution Modes: Pick Your Poison
The model supports different resolution modes depending on your needs:
| Mode | Resolution | Vision Tokens | Use Case |
|---|---|---|---|
| Tiny | 512×512 | 64 | Simple text/slides |
| Small | 640×640 | 100 | Books, reports |
| Base | 1024×1024 | 256 | Standard documents |
| Large | 1280×1280 | 400 | High-detail docs |
| Gundam | Dynamic | Variable | Complex layouts |
I typically use Small (100 tokens) for most documents. It hits the sweet spot between quality and token efficiency.
What Surprised Me: The Trade-offs
After testing this for a week, here's what I learned:
The Good
Token savings are real. I processed 50 invoices that would normally cost me ~$2 in API fees. With DeepSeek-OCR doing the heavy lifting and only sending compressed context to my LLM? Under $0.30.
Layout preservation works. The Markdown output actually respects document structure. Tables stay as tables. Headings stay as headings. This is huge for downstream processing.
Multilingual support is solid. I threw Chinese, Arabic, and mixed-language documents at it. No complaints.
The Not-So-Good
20× compression is tempting but risky. At 60% accuracy, you'll catch most content but miss details. Fine for rough drafts, dangerous for legal docs or financial statements.
Complex nested tables struggle. If your PDF has tables within tables with merged cells, expect some manual cleanup.
GPU memory matters. You need a decent GPU. I tested on an RTX 3090 (24GB) and it was smooth. Anything below 16GB VRAM might struggle with large documents in high-resolution modes.
The Cost Calculation That Made Me Switch
Let me show you why this matters financially.
Before DeepSeek-OCR:
- 10-page report = ~10,000 text tokens (1000/page)
- GPT-4 input cost: $3 per 1M tokens
- Cost per report: $0.03
- 1000 reports/day: $30/day = $900/month
After 10× compression:
- 10-page report = ~1,000 vision tokens (100/page)
- GPT-4 input cost: $3 per 1M tokens
- Cost per report: $0.003
- 1000 reports/day: $3/day = $90/month
That's an $810/month savings on input tokens alone. For a small startup processing thousands of documents daily, this is the difference between profitable and bleeding money.
When Should You Use This?
DeepSeek-OCR makes sense if:
- You're processing high volumes of documents (hundreds to thousands daily)
- Your documents have consistent layouts (invoices, forms, reports)
- You need structured output (Markdown, not just raw text)
- You want to reduce LLM API costs significantly
- You have GPU infrastructure (or can spin it up)
It's probably overkill if:
- You process 10-20 documents per month (traditional OCR is fine)
- You need 100% accuracy on every character (critical legal/medical docs)
- You don't have GPU access and can't justify cloud costs
What I Learned
Three key takeaways from this experiment:
-
Token compression isn't just about size-it's about cost. The ability to represent 1000 words with 100 visual tokens fundamentally changes the economics of document processing at scale.
-
Vision-language models are underutilized. We think of them for image Q&A, but their real power might be in efficient information representation. This feels like early days of what's possible.
-
Open source is eating AI's lunch. DeepSeek-OCR is MIT licensed, performant, and costs nothing to run locally. Three years ago, this capability would've been a proprietary API charging per page.
Try It Yourself
The model is fully open source under MIT license. Everything you need:
- Paper: arXiv:2510.18234
- Model: HuggingFace
- Code: GitHub
I'd start with the Transformers example first to get a feel for it, then move to vLLM if you need production speed.
Connect
- GitHub: @0xReLogic
- LinkedIn: Allen Elzayn

Comments